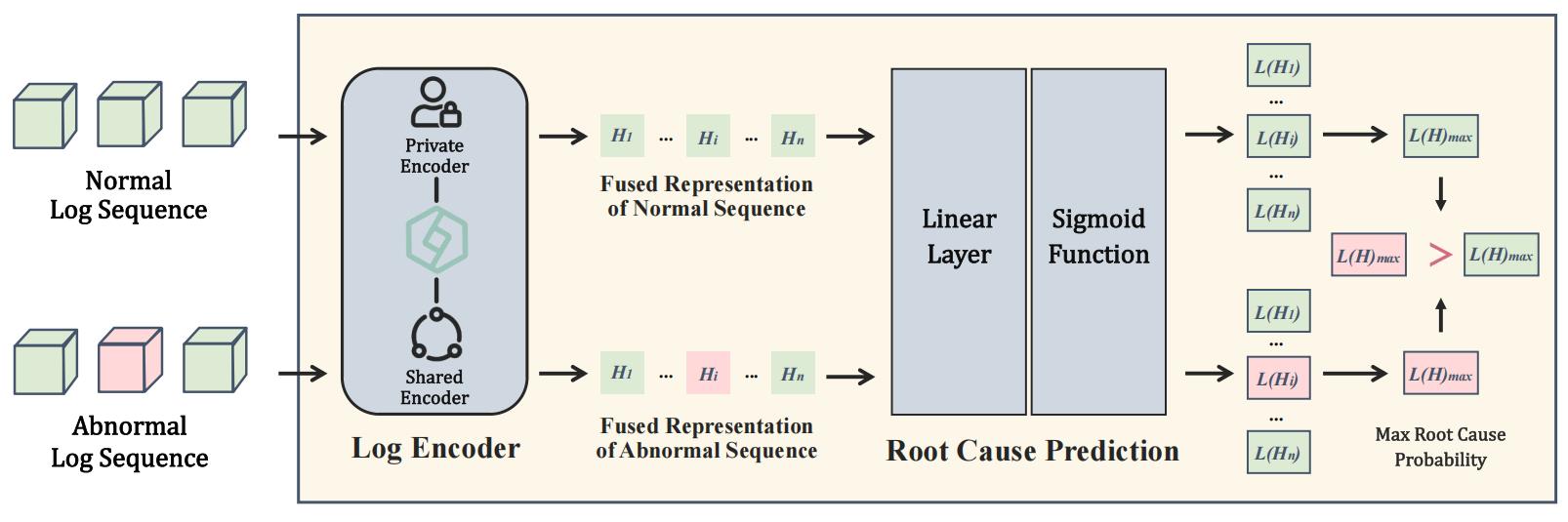
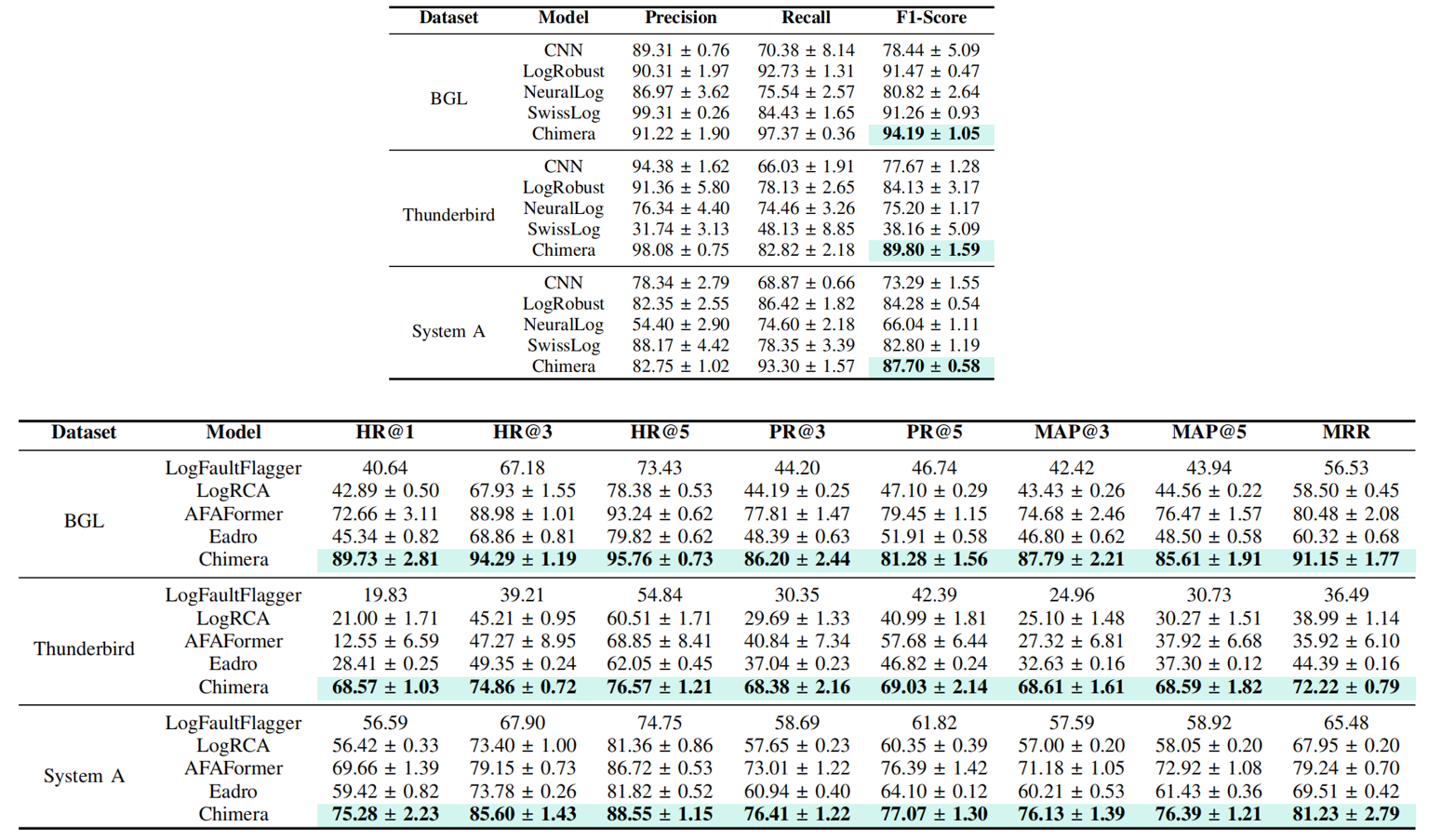
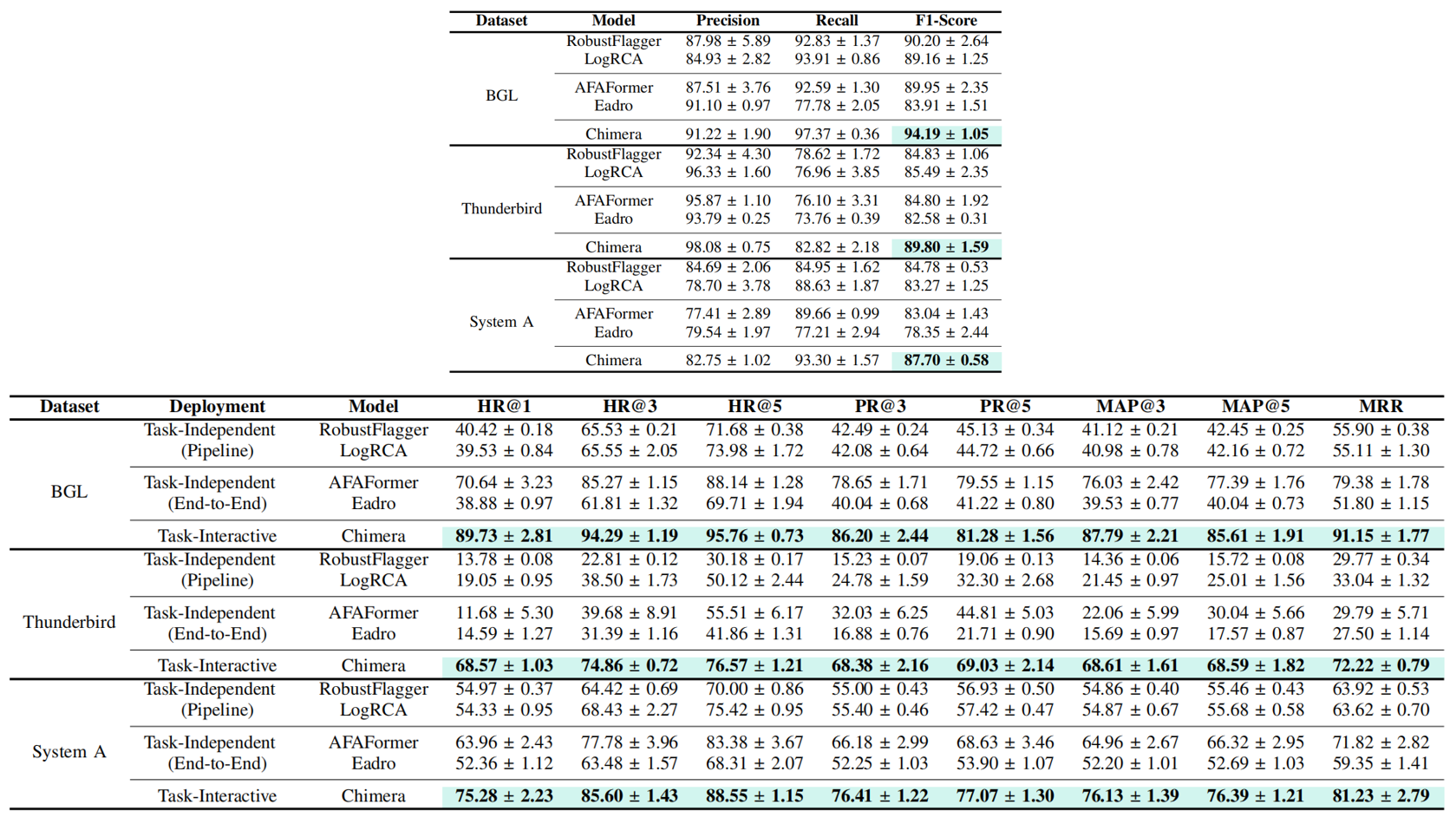
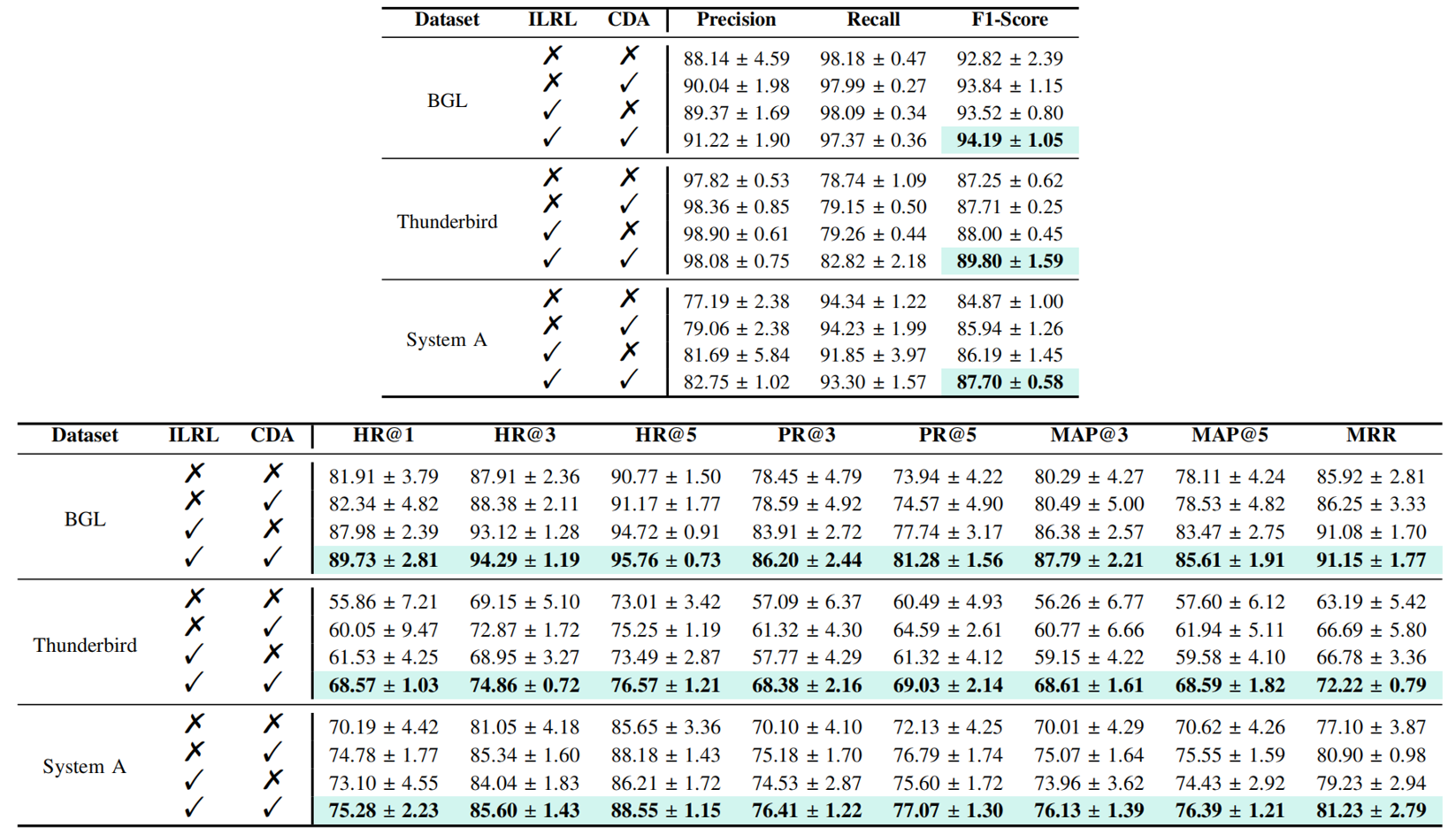
Issues: Diagnostic Bias and Suboptimal Diagnosis in Log-based Software System Fault Diagnosis
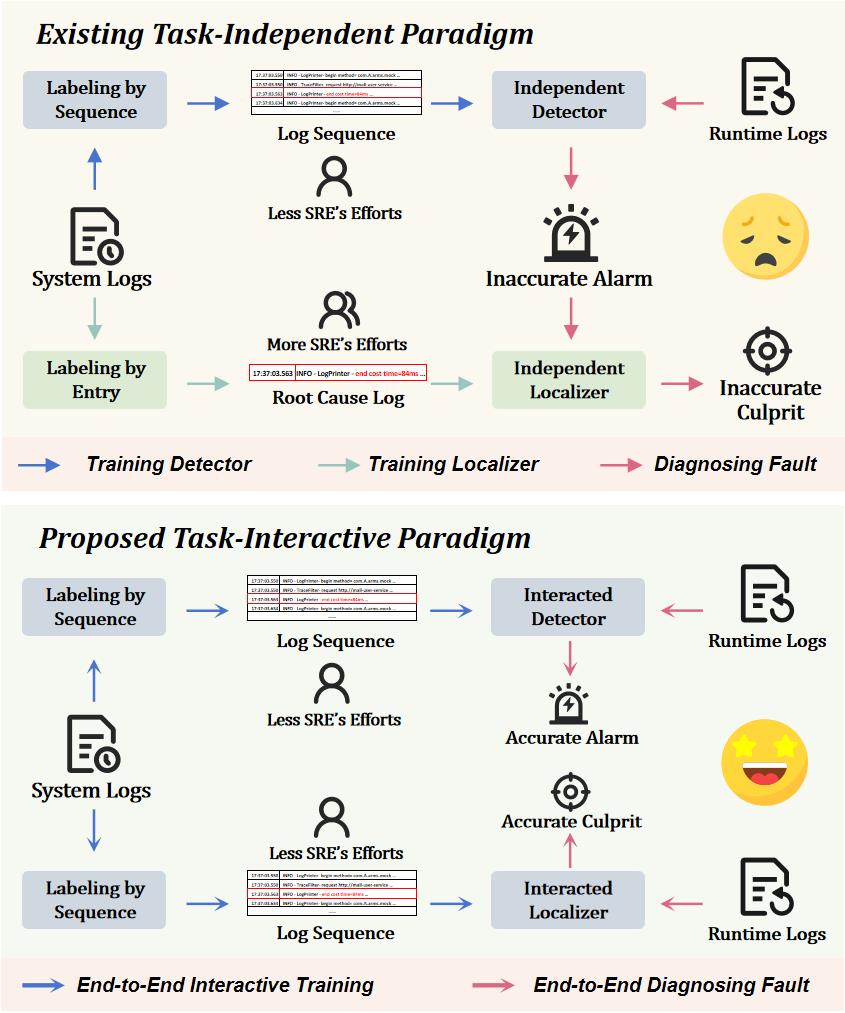
Log-based fault diagnosis are divided into two stages: 1. anomaly detection is performed first, and 2. if a fault is detected, further root cause localization is conducted.
-
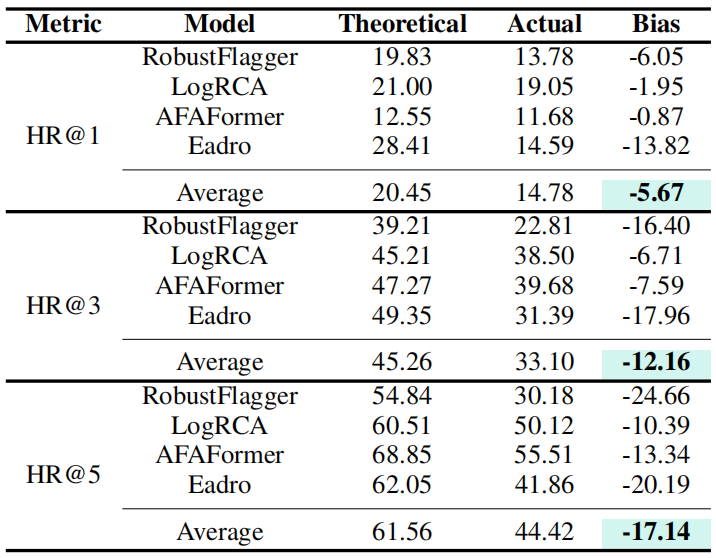
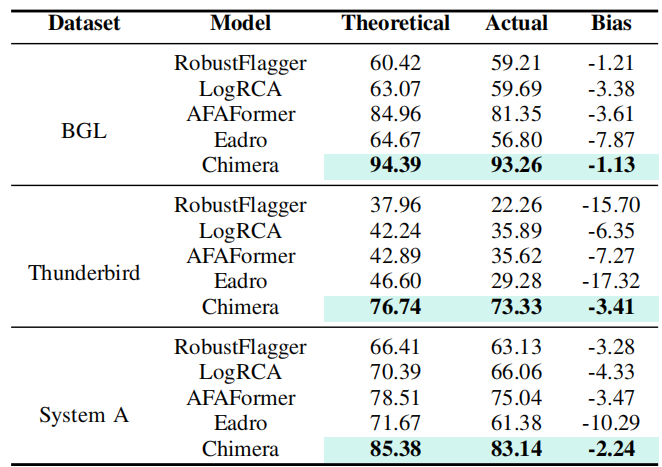
Diagnostic Bias: If the detector yields inaccurate results, these inaccuracies will also be passed on to the localizer.
-
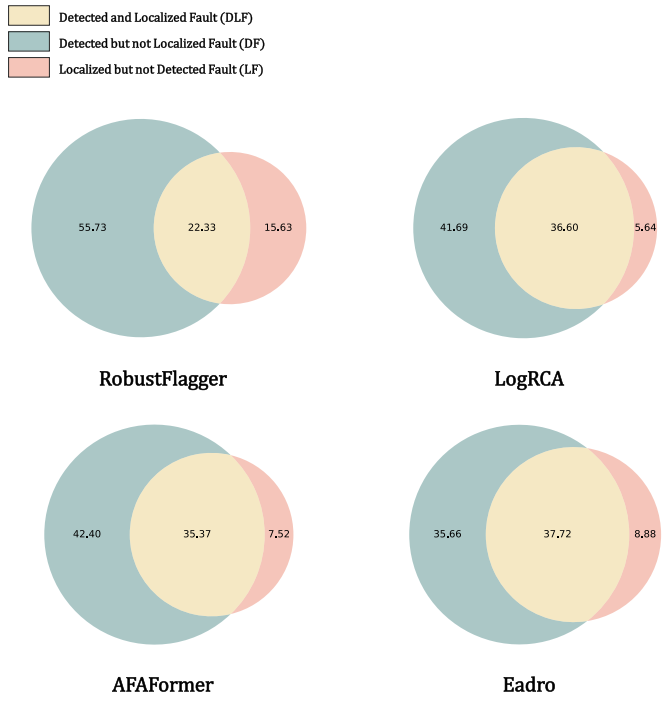
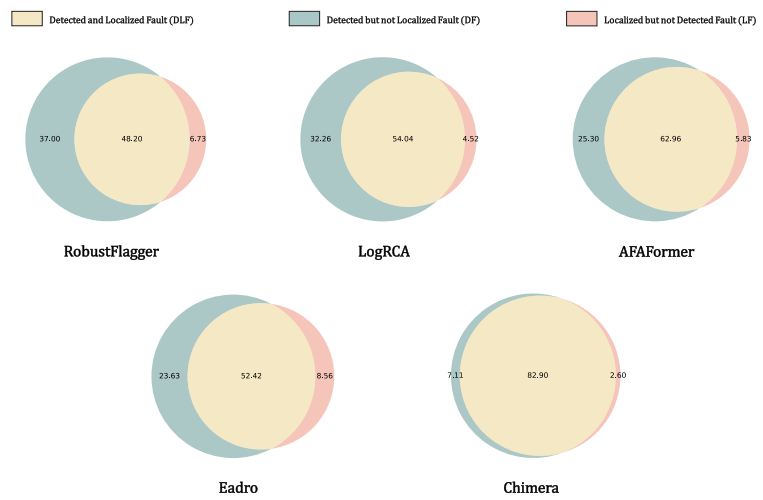
Suboptimal Diagnosis: A system fault may not be simultaneously detected and localized.
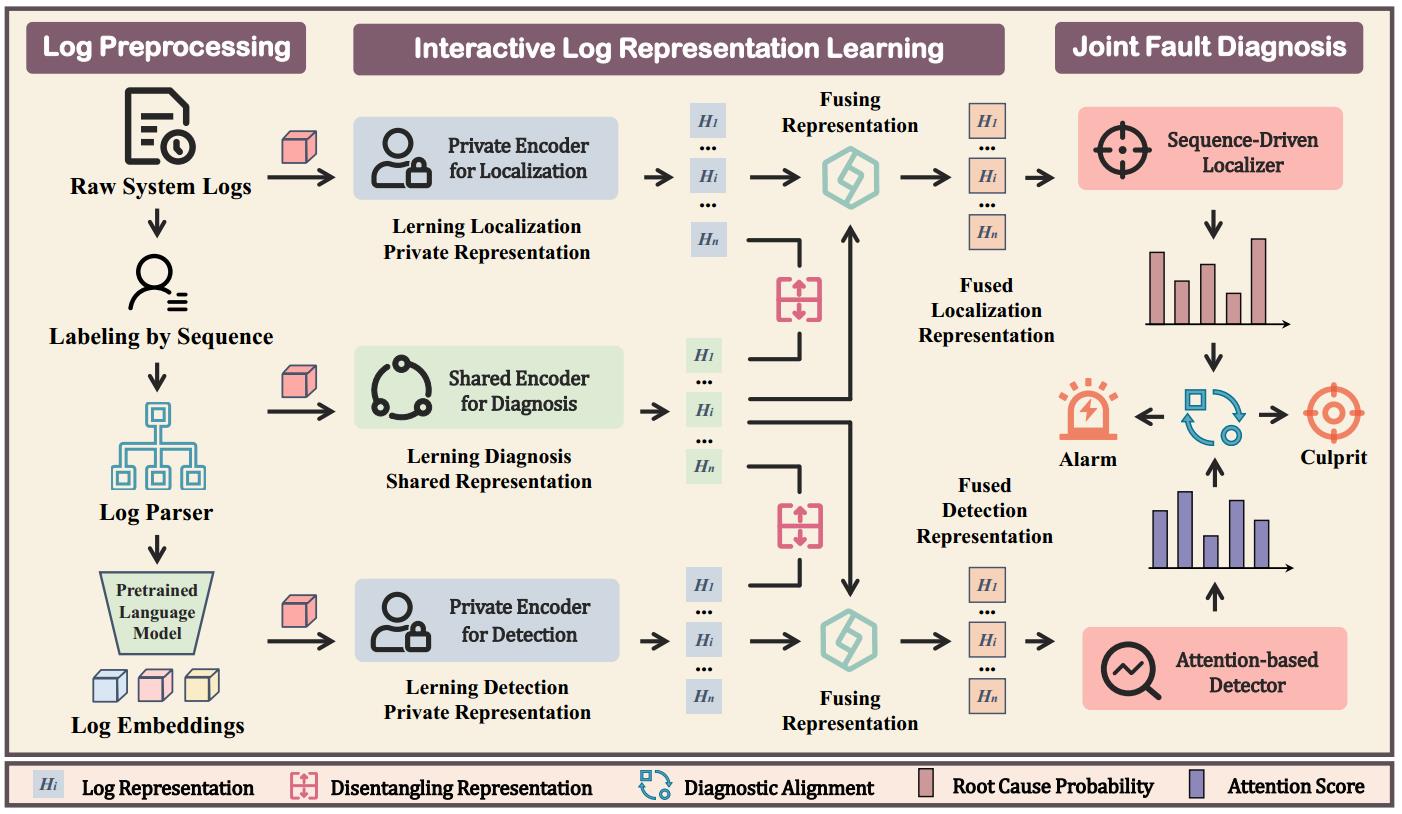
Key technologies: Bridging the gap between anomaly detection and root cause localization through their Bidirectional Interaction and Knowledge Transfer
In our view, the root cause of these issues is that anomaly detection and root cause localization rely on different forms of data for training and have distinct diagnostic objectives for faults. The anomaly detection uses anomalous log sequences as training data, with the diagnostic objective of determining whether a fault has occurred in the system. The root cause localization utilizes root cause logs as training data, with the objective of localizing the fault that caused the failure. Simply piecing together expert models to construct a fault diagnosis system cannot effectively bridge the gap between the two in terms of data forms and diagnostic objectives, nor can it handle fault diagnosis within a unified framework.
Our propose method: Chimera
Addressing these issues requires bridging the gap between the two sub-tasks in terms of data forms and diagnostic objectives, and constructing an end-to-end fault diagnosis system. Our approach is to implement interactive multi-task learning between the two sub-tasks. Our key insight is that there is a strong mutual implication between the anomaly detection task and the root cause localization task, and their bidirectional interaction and knowledge transfer can bridge the gaps in data forms and diagnostic objectives.